


本篇主要給大家分享一下Scrapy爬蟲框架,以及通過spider獲取更多美麗小知識的文章。
上圖你感興趣嗎?如果想獲取更多的文章信息,就從一起寫成爬蟲程序開始吧!
首先我們創建一個項目
scrapy startproject guoke
進入到guoke目錄執行下面的命令
scrapy genspider beauty www.guokr.com
此時使用Pycharm打開我們的新建的guoke項目,通過分析發現果殼中美麗也是技術活更多的內容加載是通過XHR請求的json數據。

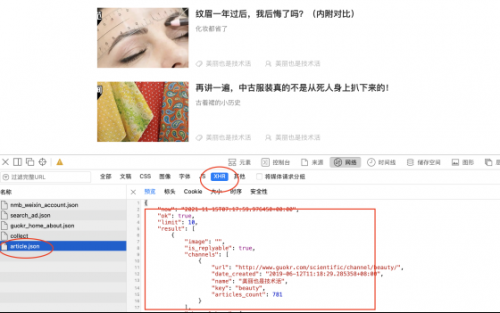
我們不僅要獲取每條json數據,還要獲取每條數據的詳情頁。

我們不僅要獲取文章的title,id,summary,url,date_created,以及要將每個詳情內容保存到txt文檔中。
爬蟲參考代碼:
import scrapy
import json
from guoke.items import GuokeItem, GuokeDetailItem
class BeautySpider(scrapy.Spider):
name = 'beauty'
allowed_domains = ['www.guokr.com']
offset = 0
start_urls = [
'https://www.guokr.com/apis/minisite/article.json?retrieve_type=by_wx&channel_key=pac&offset=0&limit=10']
def parse(self, response):
rs = json.loads(response.text)
article_list = rs.get('result')
for article in article_list:
item = GuokeItem()
item['title'] = article.get('title')
item['id'] = article.get('id')
url = article.get('url')
item['url'] = url
item['summary'] = article.get('summary')
item['date_created'] = article.get('date_created')
yield scrapy.Request(url, callback=self.parse_item, headers={'Referer': 'https://www.guokr.com/pretty',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15'})
yield item
if self.offset <= 71130:
self.offset += 10
url = 'https://www.guokr.com/apis/minisite/article.json?retrieve_type=by_wx&channel_key=beauty&offset=' + str(
self.offset) + '&limit=10'
yield scrapy.Request(url, callback=self.parse)
def parse_item(self, response):
item = GuokeDetailItem()
item['url'] = response.url
all_txt = response.xpath('//p[@style="white-space: normal;"]//text()').extract()
detail_str = ''
for txt in all_txt:
detail_str += txt
item['detail'] = detail_str
yield item
items.py參考代碼:
import scrapy
class GuokeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
summary = scrapy.Field()
date_created = scrapy.Field()
class GuokeDetailItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
detail = scrapy.Field()
在爬取過程中可能出現一些常見的錯誤代碼,如下:
Frequentresponse with HTTP404,301 or 50x errors
(1)301 MovedTemporarily
(2)401unauthorized
(3)403forbidden (aAatch處理的)
(4)404 notfound
(5)408 requesttimeout
(6)429 too manyrequests
(7)503 serviceunavailable
解決辦法:
在settings中將rebots改為False
在settings中將DOWNLOAD_DELAY 適當設置一個時間,默認是0
設置中間件middlewares
具體步驟如下:
在settings中添加USERAGENTSLIST,內容如下
USER_AGENTS_LIST = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
新建一個python文件,名字可以是:useragentmiddlewares.py,在里面添加如下代碼
import scrapy
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class MyUserAgentMiddleware(UserAgentMiddleware):
'''
設置User-Agent
'''
def __init__(self, user_agent):
super(MyUserAgentMiddleware, self).__init__(user_agent)
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('USER_AGENTS_LIST')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent
c. 在settings.py中添加MyUserAgentMiddleware
DOWNLOADER_MIDDLEWARES = {
'guoke.randomAgentMiddleware.MyUserAgentMiddleware' :400,
'guoke.middlewares.GuokeDownloaderMiddleware': 543,
}
此時就會發現一些錯誤就不見了,因為爬取速度過快或者一直是同一個瀏覽器,會被對方識別為爬蟲進行反扒處理。
pipelines.py的代碼如下,主要是存儲數據
useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import csv
from guoke.items import GuokeItem, GuokeDetailItem
class GuokePipeline:
def __init__(self):
self.article_stream = open('articles.csv', 'w', newline='', encoding='utf-8')
self.f = csv.writer(self.article_stream)
def process_item(self, item, spider):
if isinstance(item, GuokeItem):
data = [item.get('id'), item.get('title'), item.get('summary'), item.get('url'), item.get('date_created')]
self.f.writerow(data)
elif isinstance(item, GuokeDetailItem):
url = item['url']
id = url[:-1].rsplit('/')[-1]
with open(str(id) + '.txt', 'w') as stream:
stream.write(item['detail'])
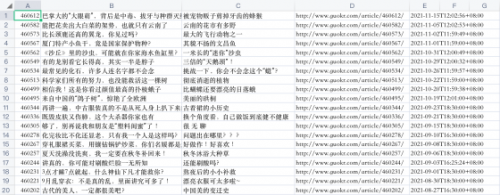
完畢之后,我們就可以運行爬蟲進行測試了。
scrapy crawl beauty
結果展示一下:

打開文本看一下

當然因為在解析的時候我是把里面的換行給去掉了,所以沒有一些換行的效果,大家可以再次優化一下上面的spider.py里面的代碼。
更多關于python培訓的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓服務經驗,采用全程面授高品質、高體驗培養模式,擁有國內一體化教學管理及學員服務,助力更多學員實現高薪夢想。















 京公網安備 11010802030320號
京公網安備 11010802030320號